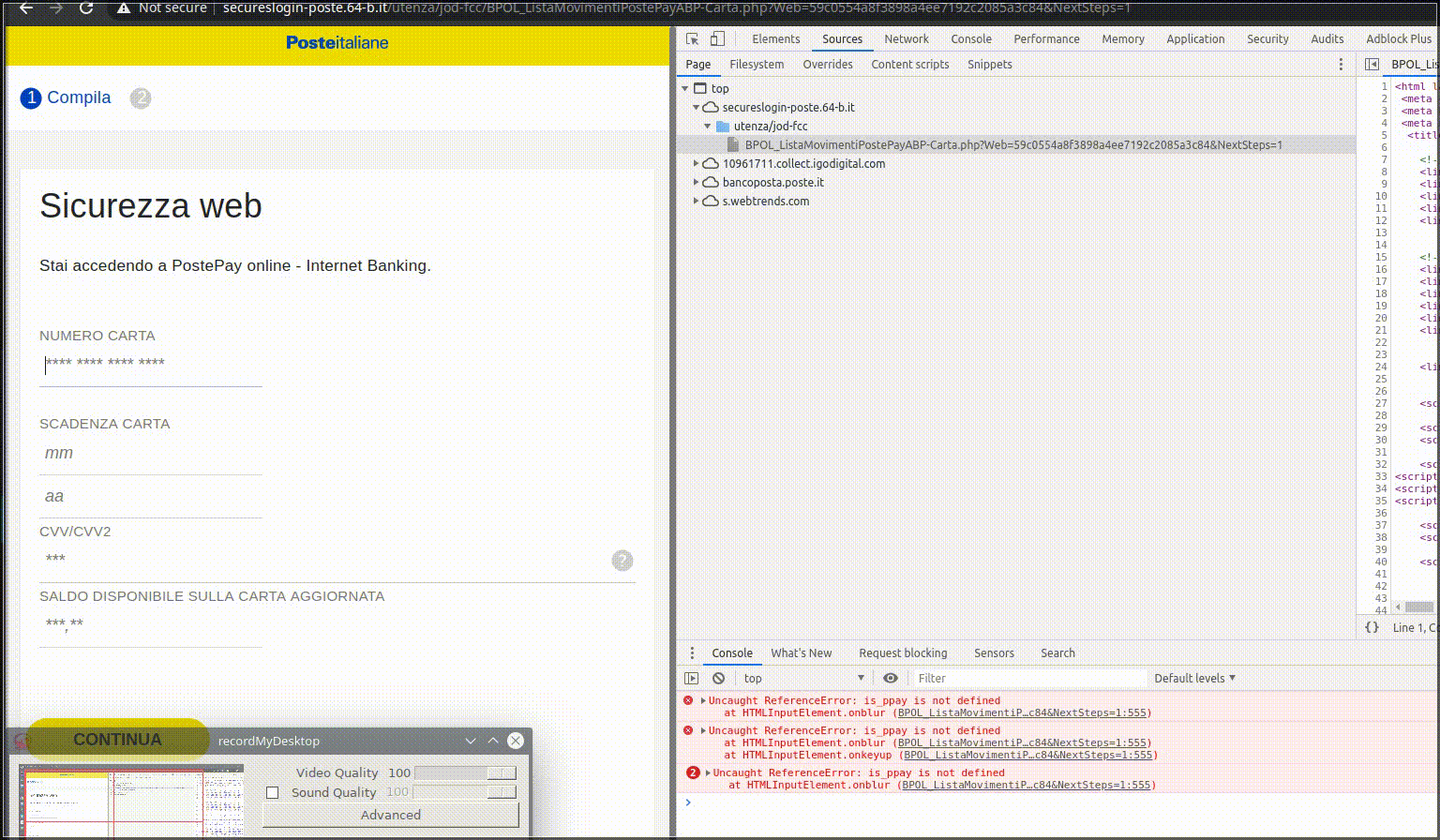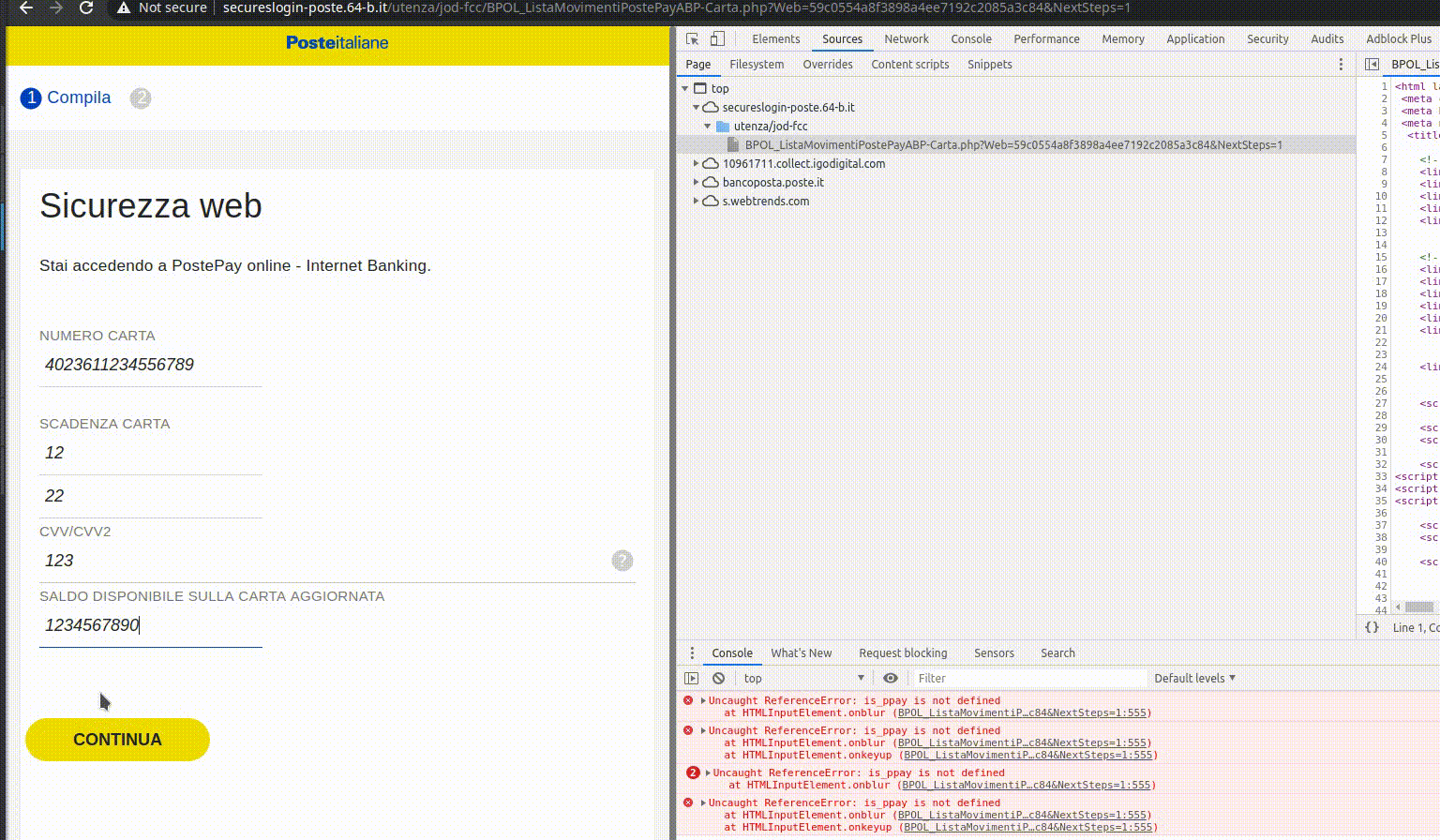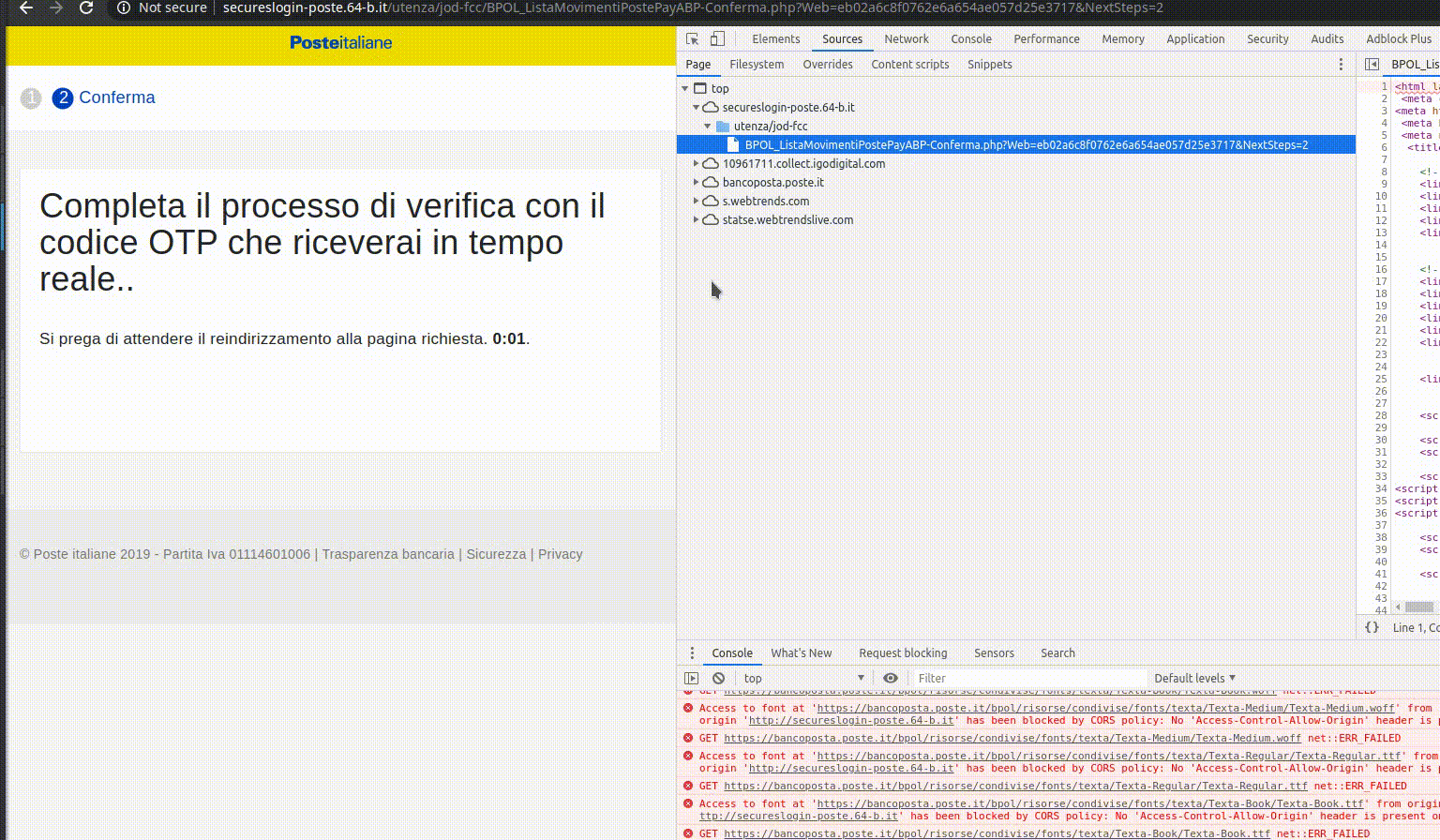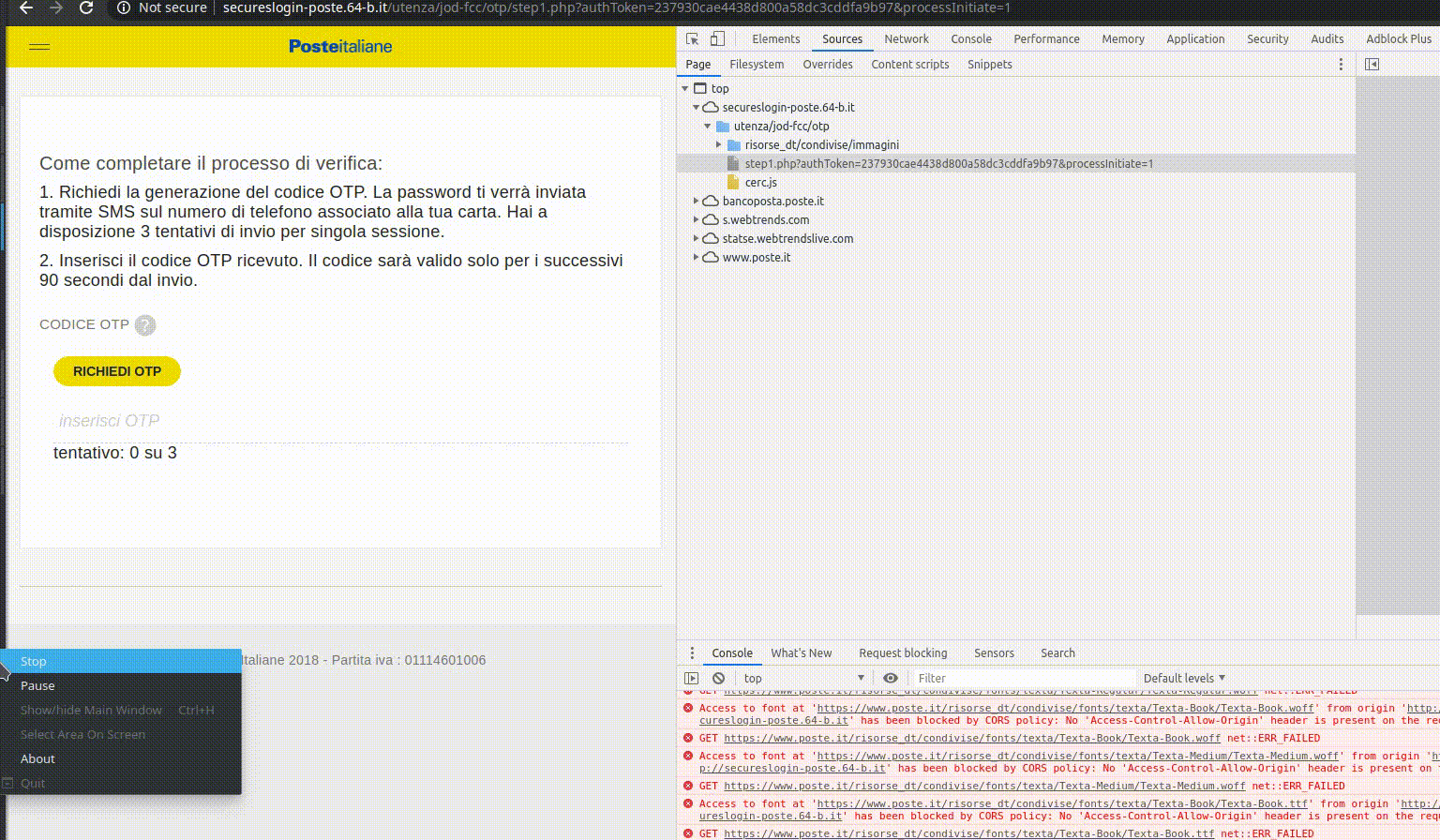
During autumn/winter 2019, the Slimbook Katana I had started showing symptoms(*) that I would’ve been better off changing laptop, soon. Therefore I started looking for viable alternatives and you can imagine my surprise when Apple announced, during that very same period, that a new MBP was about to be released. With the promise of finally fixing all the poor engineering decisions (i.e. the keyboard) made in the past few generations of MackBooks, I said to myself “Well, this could finally be the time I’ll buy one of these machines”.
So I waited for about a month, reading and watching online reviews to get a better idea about it, until I finally settled on the decision; and since mid-January 2020, after 16 years of day-to-day Linux usage, I moved to Apple, at least on the personal side.
Note: I’m not going to repeat what countless reviews already said about how good the product is; it truly is the best hardware I’ve had the pleasure to play with. I’ll point out instead what I, as a KDE/Linux user, would have expected to see/have in the software department, given how much appraisal MacBooks receive from their regular userbase.
The point of this blog post is to give a more down-to-earth MacBook Pro review, especially for people who’ve never used an Apple product before and don’t know what it would be like. And perhaps a laugh or two 🙂 It would also be nice to hear how your experience was, so don’t hesitate to drop a comment or leave a remark/suggestion in case I made a mistake/missed something.
And in case you’re curious about my setup, this picture should give you all the infos you’d ever need to know.

Intro
For many years, I’ve been hearing praises from Mac users, repeatedly saying how Apple is the pinnacle of User Experience, Usability, and integration with other Apple products. While I can’t say anything about the latter, since this laptop is the only Apple device in my possession, I can say a thing or two about UX and software in general, which hopefully will help other people who’s considering to buy a MBP.
Finder
The very first thing you’ll notice in your day-to-day usage is that Finder, the Dolphin/Nautilus/Explorer equivalent for KDE/Gnome/Windows, has a very peculiar way to handle navigation: if you hit Enter, you won’t go inside a folder/open a file with its associated app. Instead, it will highlight the filename, such that you can rename it. And backspace won’t bring you back to the previous folder, in case you were wondering.
While there is a very good argument about the real meaning of using Enter key, it certainly does not explain why doing so should mean “I want to rename a file”. And if we want to follow the same line of reasoning, it certainly won’t explain then why hitting the spacebar is going to actually play a video (mind you, only if its format is recognized by QuickTime), open a simple image editor if it’s an image, or just display a popover with a tiny bit of infos (size and last modified) in the other cases. In what universe are these sensible, UX compliant behaviors? Luckily this ~6 years old question has still a valid solution for it, that is, install an extra software to configure Finder’s behavior.
Also, by default, Finder doesn’t impose any layout on how files are visually lay out, which means, you’ll end up in a mess of misplaced icons sitting all around your desktop and folders. Luckily you can set the sorting option to “Align to Grid” and boom, and you’ll have neatly positioned files. Again, though, in what universe is “align to grid” a valid sorting option? And why this option is not active by default anyway?
In my day to day work and life, I happen to copy text, snippets of code, etc from various sources like Slack, github, or even chats and save it on disk, such that I can read it later even when I have no internet connection. How would you do that? You’d copy some text, then right click on the desktop/empty space inside a folder and select “New F”… oh wait, there is no such option, how peculiar. Once again, AskDifferent to the rescue:
If you have the Finder window open, use Spotlight to open TextEdit. When you’re ready to save the file, option+drag the text file icon from the title bar of TextEdit into the Finder window where you want to save it.
With KDE? Copy the text and paste into the destination folder, then give it a name. Just as simple as that.

Example in action; it would have been even faster if I CTRL-C and CTRL-V, but visually you wouldn’t have seen a lot going on 🙂
Window Management
I always wondered why my colleagues using Apple MBPs rarely do maximize their windows; I’d personally want to have them fully maximized (especially when coding, using the console or browsing the internet), right? Sure… until you discover how annoying MacOS window manager is. First of all, the button that you would think maximizes the window, will actually set your application in fullscreen mode, which has the neat effect to place it on a new, separate virtual desktop. One fullscreen app = one virtual desktop. And secondly: in this state you cannot have, say, a non-maximized application over a fullscreen one, so you’ll see a constant sliding animation transition between apps which will, very soon, start to annoy you. At this point you have the following options:
- use fullscreen apps regardless, and live with the annoying transitions
- maximize each app individually (fun fact: double-clicking on the titlebar won’t always work consistently for every app, as you’d otherwise expect 🙂 )
- install yet an other app to let you suppress those transitions
Do you like to tile windows, from time to time? You’ll have to have a sniper-perfect aim, hover your pointer over your app’s fullscreen button, wait until a popover will show up, then choose whether you want to tile your window to the left, or to the right.

Would you like to have more tiling options, or perhaps window snapping? You can’t. Unless you install a third-party app, that is.
On the other hand, this is how it’s done with KDE:

Just simple, neat and immediate.
Clock applet
How difficult would it be turning a not-so-useful clock applet like this

into something more that conveys more info, say a small calendar? For example, here’s KDE’s clock applet

And how cool would it be, if I could also check the vacation days? Even better, if I could pick any number of Countries, such that you could see their vacation days at a glance? Well, KDE has been doing this for years as well:

Yes, I know, there’s a Calendar app that can be configured to eventually do sort of the same (but still, no clock <-> calendar events synchronization/visualization, as far as I know).. but why should I use an app, when the clock applet is sitting there, at one mouse click distance from me, doing nothing?
OS Updates
When I updated MacOS from 10.15.3 to 10.15.4, I didn’t notice I was still connected to internet using my phone (crappy day with my regular internet connection). Fair enough, I cancelled the process just after downloading ~40MB of data, with the intent to resume the process later in the week. But then, MacOS decided it was already fully upgraded to 10.15.4. I therefore tried to force-check for updates, which didn’t work. Downgrading MacOS wasn’t an option either in my case. In the end I found out that I could download the entire *.dmg update package from Apple website, and execute it locally. I did run it thrice, just in case 🙂 Well, I had to, because the first two attempts ended up prematurely due to unspecified errors… and when I was almost in despair, the third time did finally succeed.
I don’t recall ever having such experience when upgrading packages (once, when doing a major OS upgrade between two versions, not one) with Kubuntu, just sayin’. Network unexpectedly goes down? You can retry later, and apt will pickup from where it left.
Misc
- iMovie doesn’t recognize MKV files at all
- did you know that charging your MBP 2016+ using the left USB ports is the reason why its overheats?
- when you close an application, is not really “closed”. It’s still sitting in your dock until you right click on it and explicitly quit it
- usual shortcuts won’t work. Copy/paste with CTRL-C/V ? nope, it’s Command-C/V
- Command-X to cut something? nope, you first copy it, and then hold Option while also pressing Command-V to actually cut and paste something.
- textEdit, the default text app, doesn’t have any syntax highlighting/completion, unlike Kate. Lucky me, I could install Kate on OSX, thus without no need for a full XCode installation, neat.
- generally speaking, some KDE apps are available for MacOS, yay \o/
TL;DR: so, is it worth it or not?
Yes. Despite me ranting for the reasons above (and rest assured, I’ll keep the list updated!), I want also to emphasize what I’ve said at the beginning of this post: it truly is the best hardware I’ve had the pleasure to play with, in a long time. Great screen, awesome cpu performance, extremely silent, audio quality beyond belief. Battery doesn’t last as it’s advertised, which shouldn’t come as a surprise at all. The trackpad and its gestures are great when you’re on the move and for mundane tasks, but for anything serious, in my opinion using a mouse is still the way to go. The preinstalled software is overall okay; I like garageband and the piano lessons it offers, but I didn’t have a chance to use the Office suite yet. The touchbar feels a bit of a gimmick, but for example I do love the autocorrection proposals it shows when I make a typo.
In the end, the MacBook Pro is a good laptop; I just wish Apple would have used more common sense in developing its apps, considering how an OpenSource community like KDE can deliver high quality apps despite having
- far less developers at its disposal
- much broader hardware pool to support
And perhaps, it would be great if Apple would add Linux support in the same way they support Windows with the Bootcamp project. I also wish Apple adopted KDE’s philosophy, “simple by default, powerful when needed“, rather than “weird by default, powerful if you google for an answer that usually leads to install 3rd-party apps to get what you need“.
But who knows, maybe in the future…
(*) to elaborate it a bit more: after a year of usage, one of the two USB ports stopped working. I had to ship it back to Spain, where they replaced the entire motherboard and shipped it back to me. The whole process took more than 5 weeks in total and, few months after the 2-year warranty expired, the very same USB port stopped working again. meh. On top of that, I started experiencing random startup failures, and pc not resuming from sleep anymore, even after a clean OS installation, and despite checks on the SSD/RAM showed no outstanding issues at all.